考公报名,但是 JS & Python 赋能
前言
去年3月,我第一次报考广东省公务员,
人生地不熟,也没有进面;
今年1月,我闲着也是闲着又报了一次,
这次在报名阶段加入了一些自己的小技巧,
现分享给大家。
另外,本次报考依然没有任何准备,
如果硬要说有就是考前1天花1元重金买了2套冲刺卷,
但只是看了一眼题型。

不对考试结果抱任何希望,
但一旦有幸进入面试就会厚着脸皮去,
然后写(笔试)速通经验以及面试速通失败经验。
职位筛选
报名的第一步是从公告最下方附件下载职位表:
初筛
打开 Excel, 启用编辑,以启用接下来的筛选功能。操作简单,不再赘述。
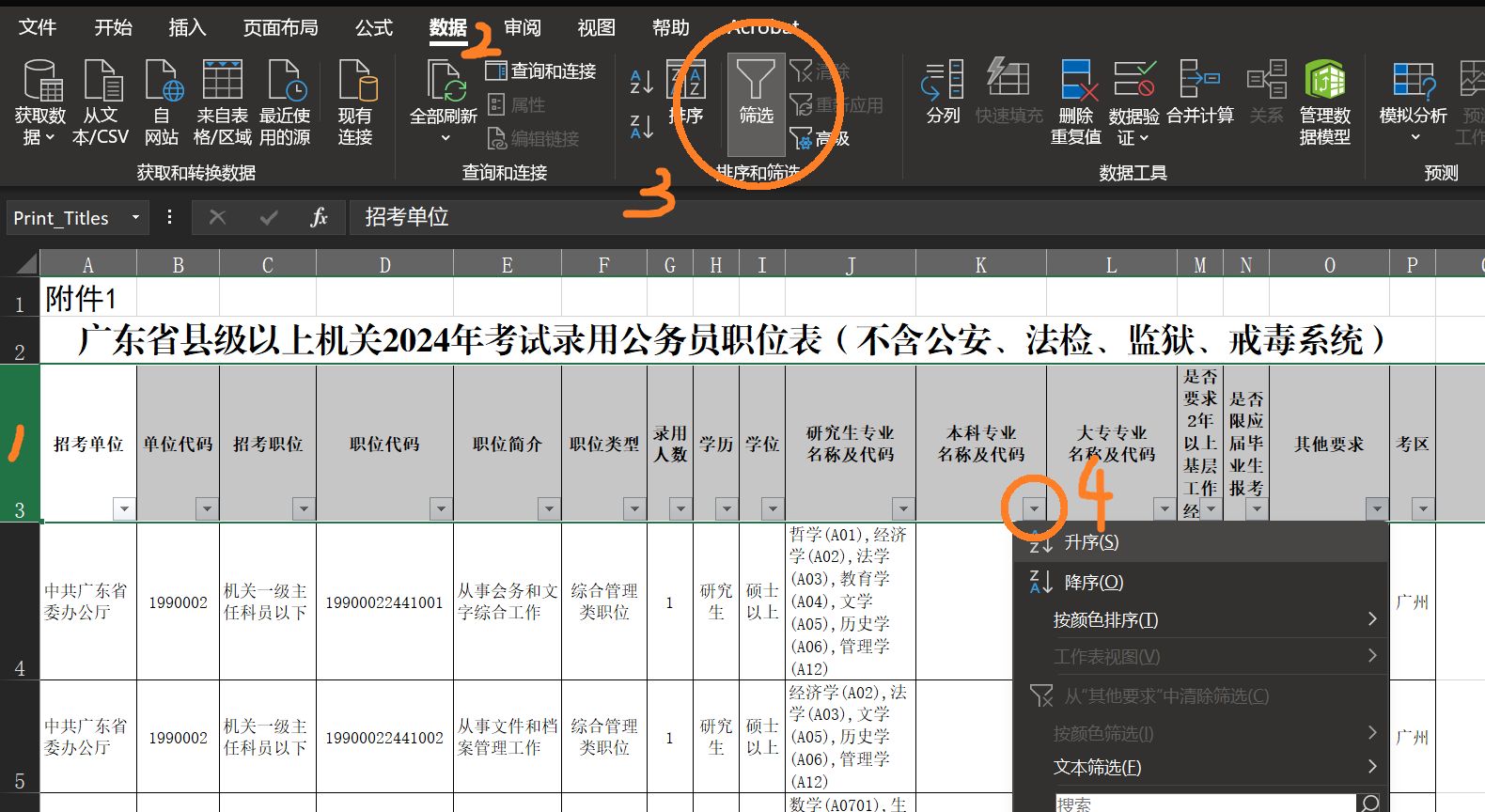
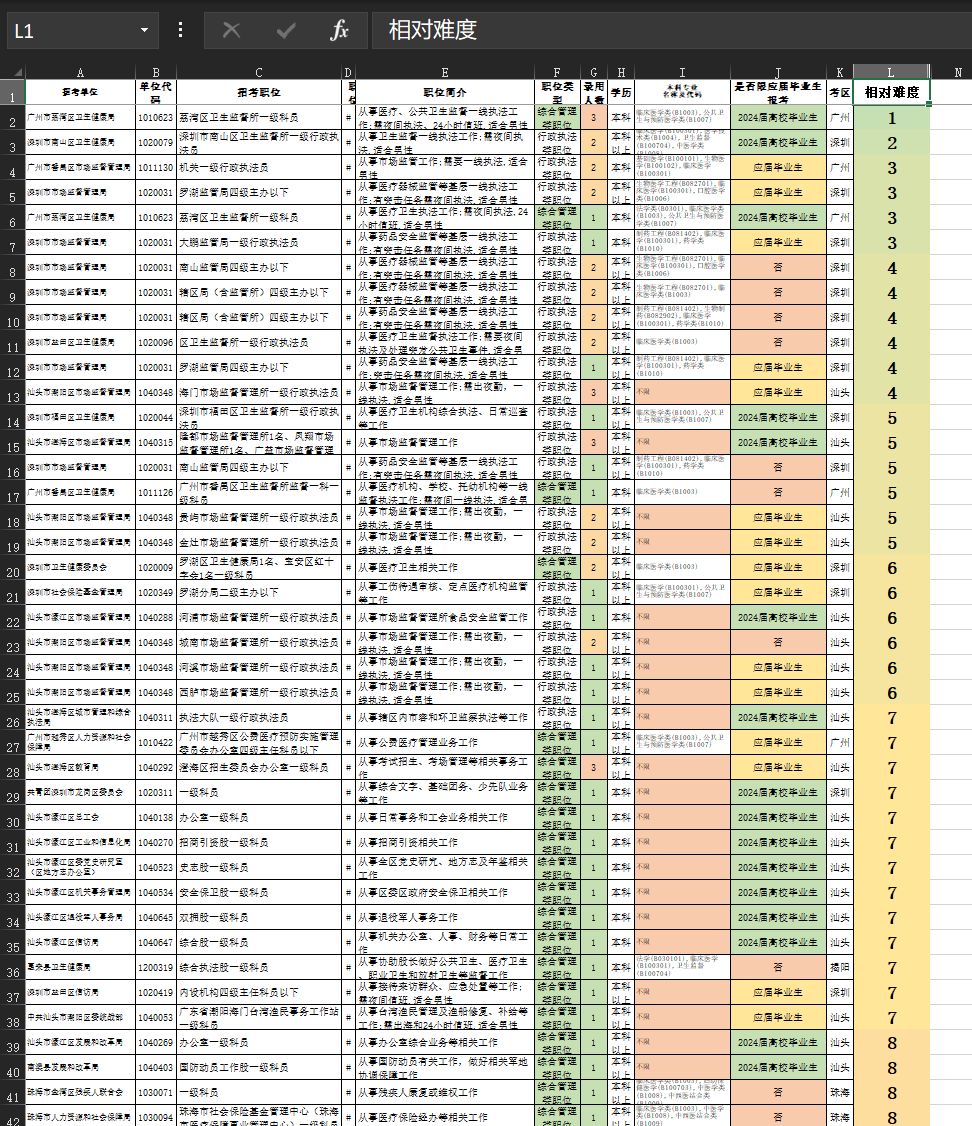
相对难度
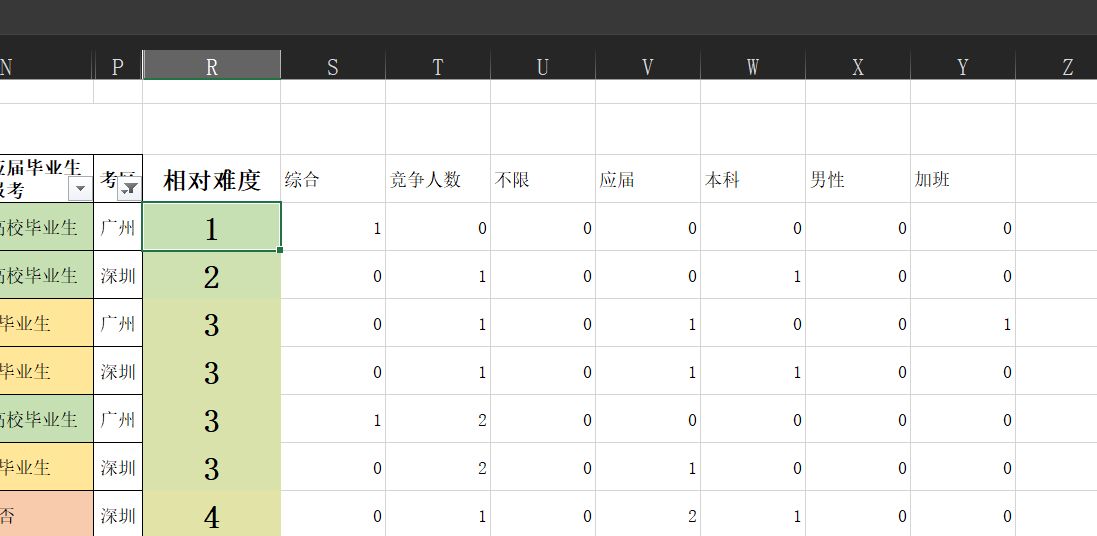
本节通过 Excel 公式,计算每个职位的相对难度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # 总分
Rn = Sn + Tn + Un + Vn + Wn + Xn + Yn
# 综合类比执法类难度更大
Sn = IF(Fn="综合管理类职位",1,0)
# 竞争人数,拿最大值3减
Tn = MAX(0, 3-Gn)
# 限制专业则报名人数少,竞争小
Un = IF(Kn="不限",2,0)
# 当年应届 < 应届 < 非应届
Vn = IF(Nn="2024届高校毕业生",0,IF(Nn="否", 2, 1))
# 本科 < 本科以上
# 本科就是只能本科,本科以上则硕士博士也能来报名
Wn = IF(Hn="本科",0,1)
# 是否限制性别
Xn = IF(ISNUMBER(SEARCH(X$3,En)),0,1)
# 是否要求夜班
Yn = IF(OR(ISNUMBER(SEARCH("夜", En)), ISNUMBER(SEARCH("24", En))),0,1)
|
这样,就可以根据难度排序,选出理论上最容易考的职位了
人数监视
筛选出可以报名的职位,
正式报名之前,
最重要的参考依据就是每天下午 16:00 公布的已报名人数。
毕竟相对难度只是理论值,
而一个难度拉满的职位如果只有1人报考,
那么就等于保送。
Official Approach
查询报名人数,首先打开左侧职位报名统计页面:
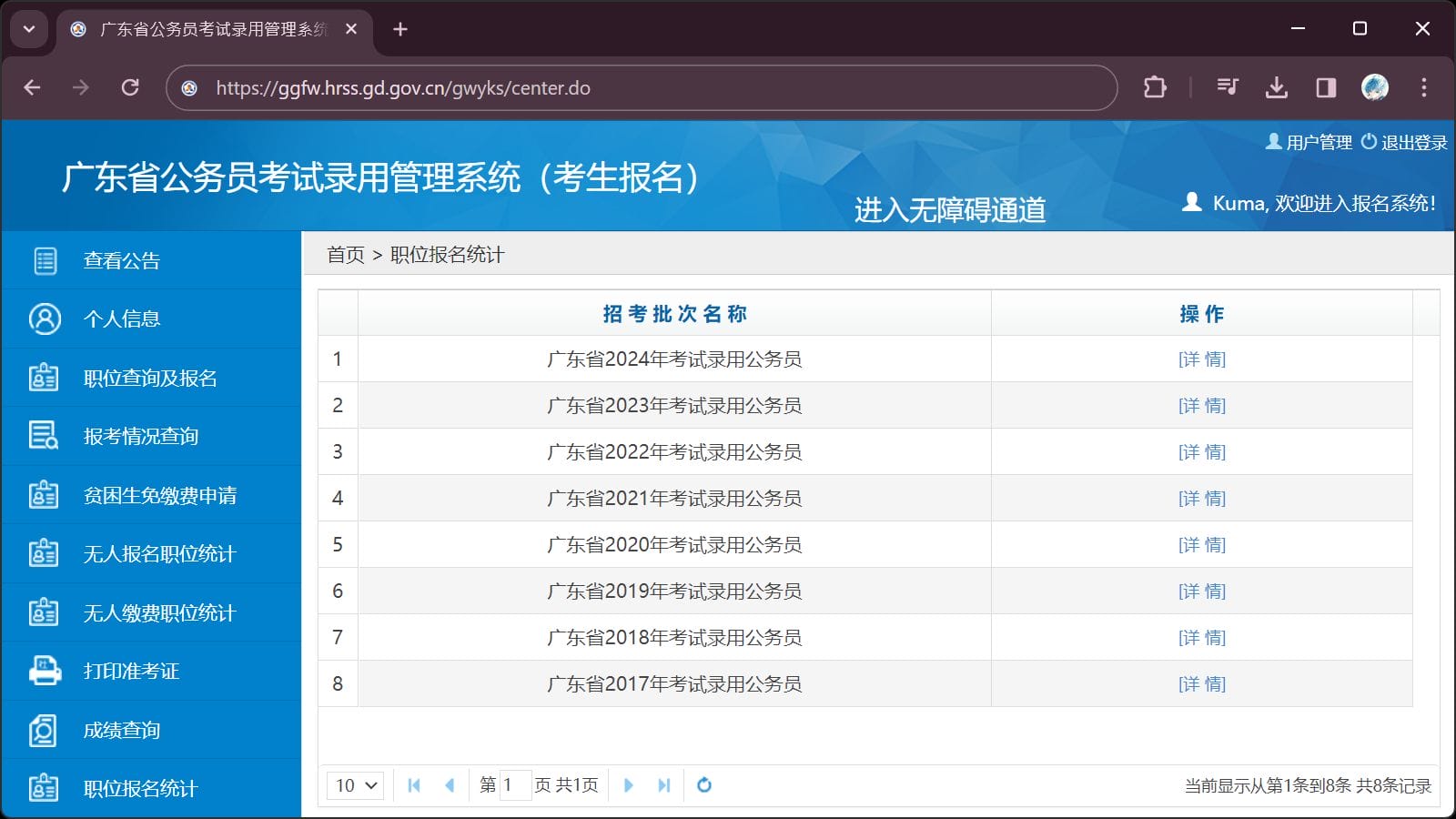
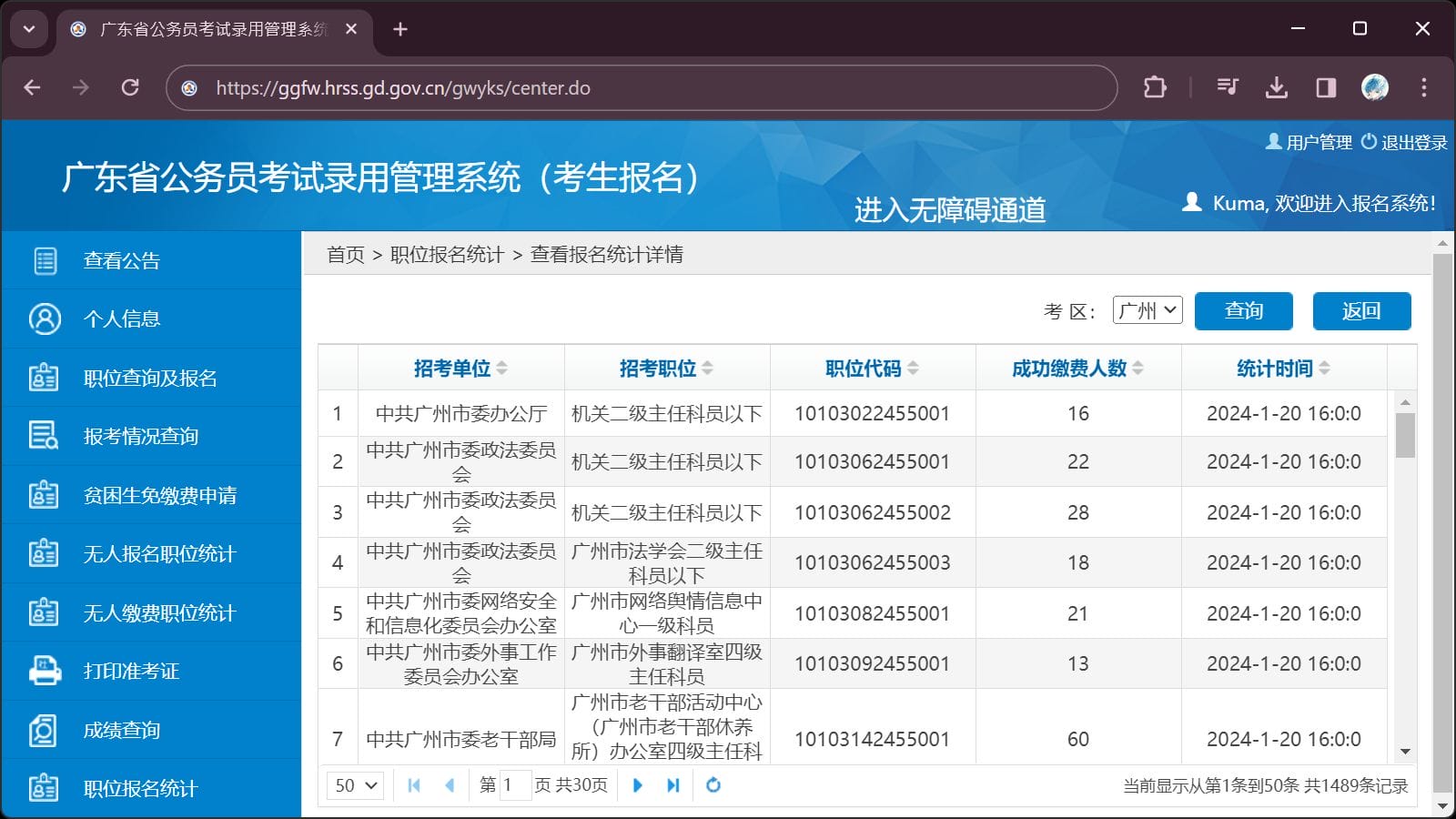
然而,每页最多显示 50 条数据,
寻找目标职位需要通过职位代码定位,
也就是说需要多次翻页:
而且,如果翻页过于频繁还会弹窗拒绝:
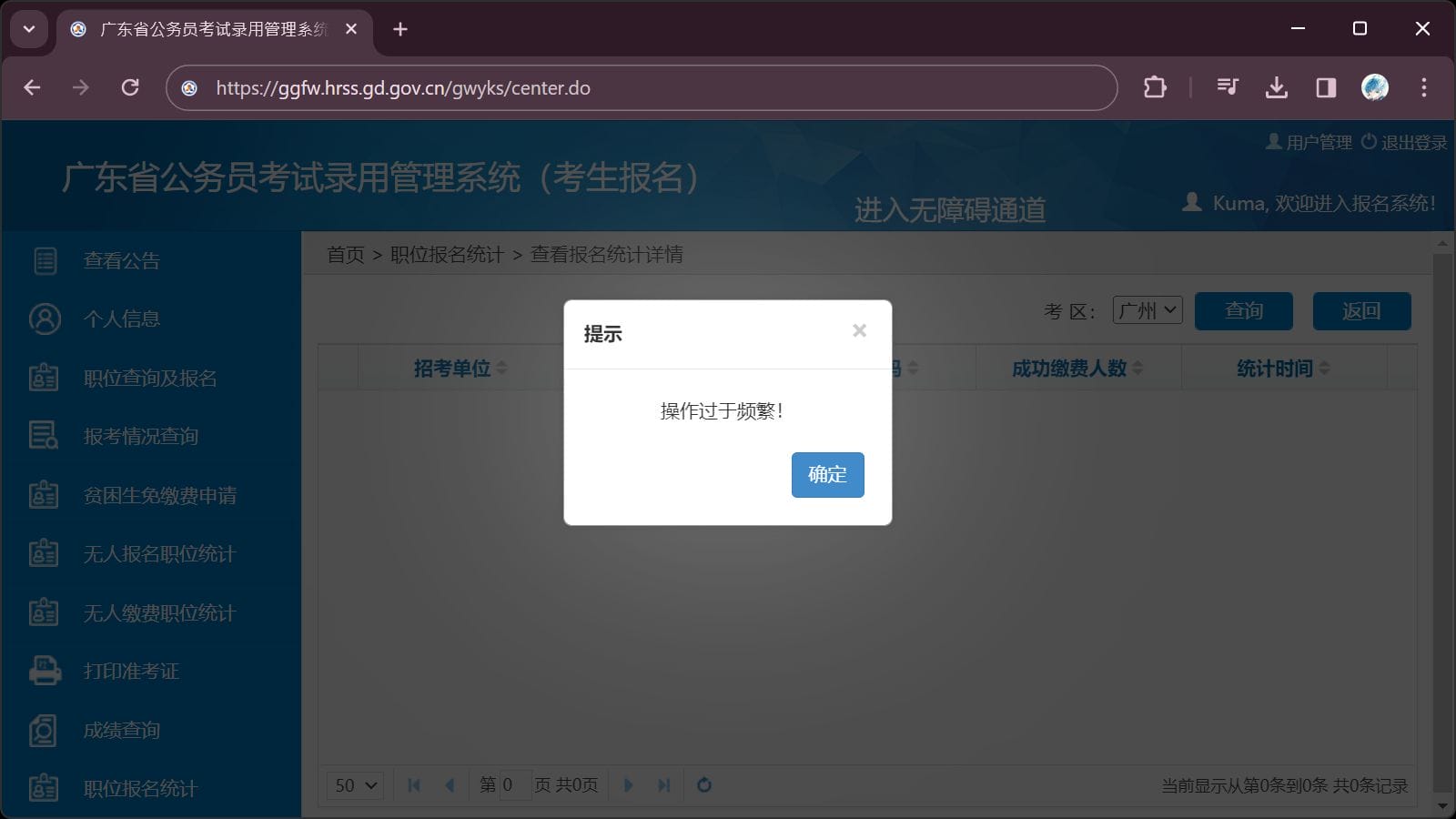
也就是说,如果筛选了60个职位,
每次查询至少需要1分钟,
则完成一轮查询需要1小时!
自动化查询
获取 / JavaScript
首先开启开发者工具,
进行一次查询,查看请求:
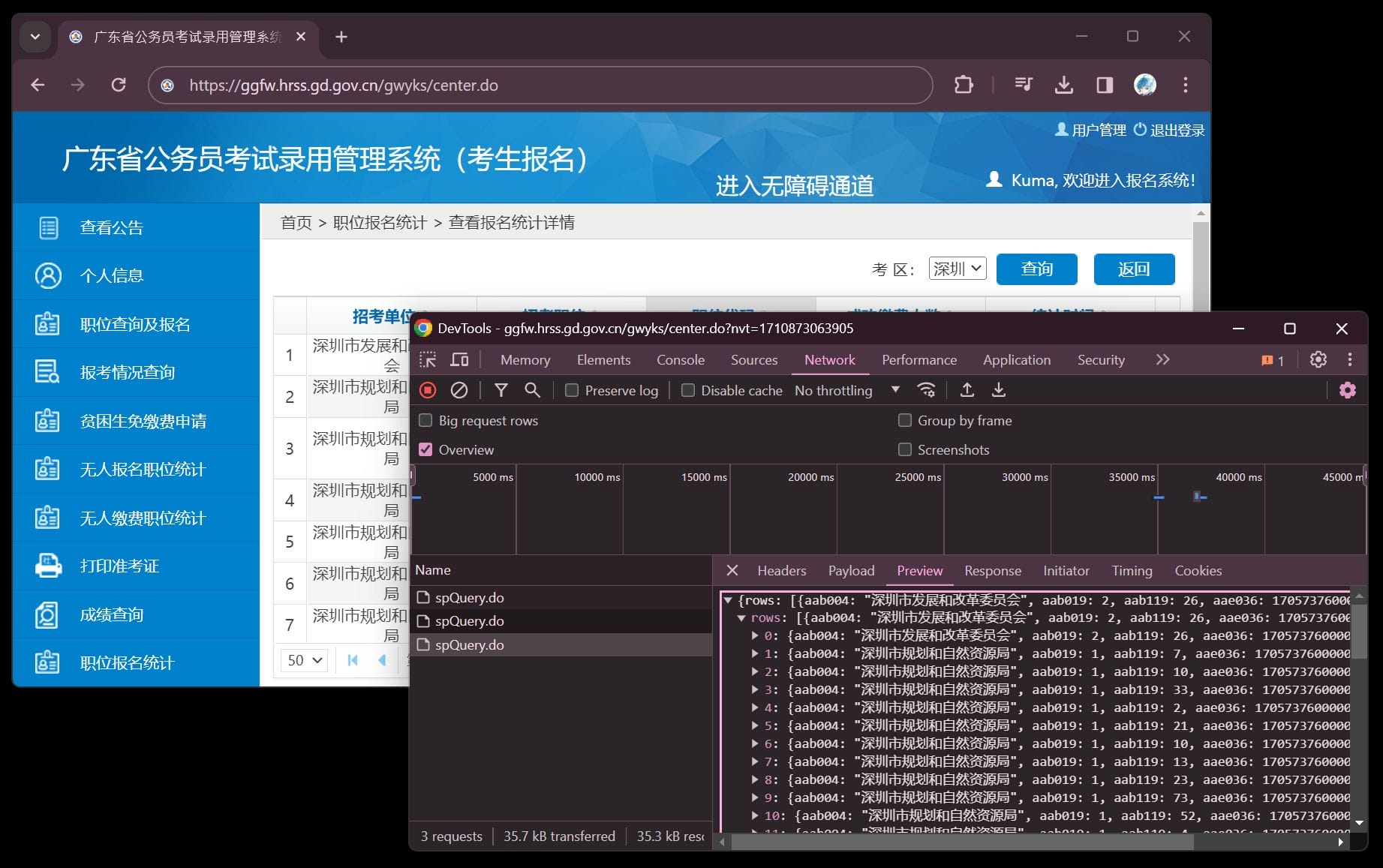
右键请求,点击 copy as fetch
(复制为 JavaScript, 可以直接在控制台运行),
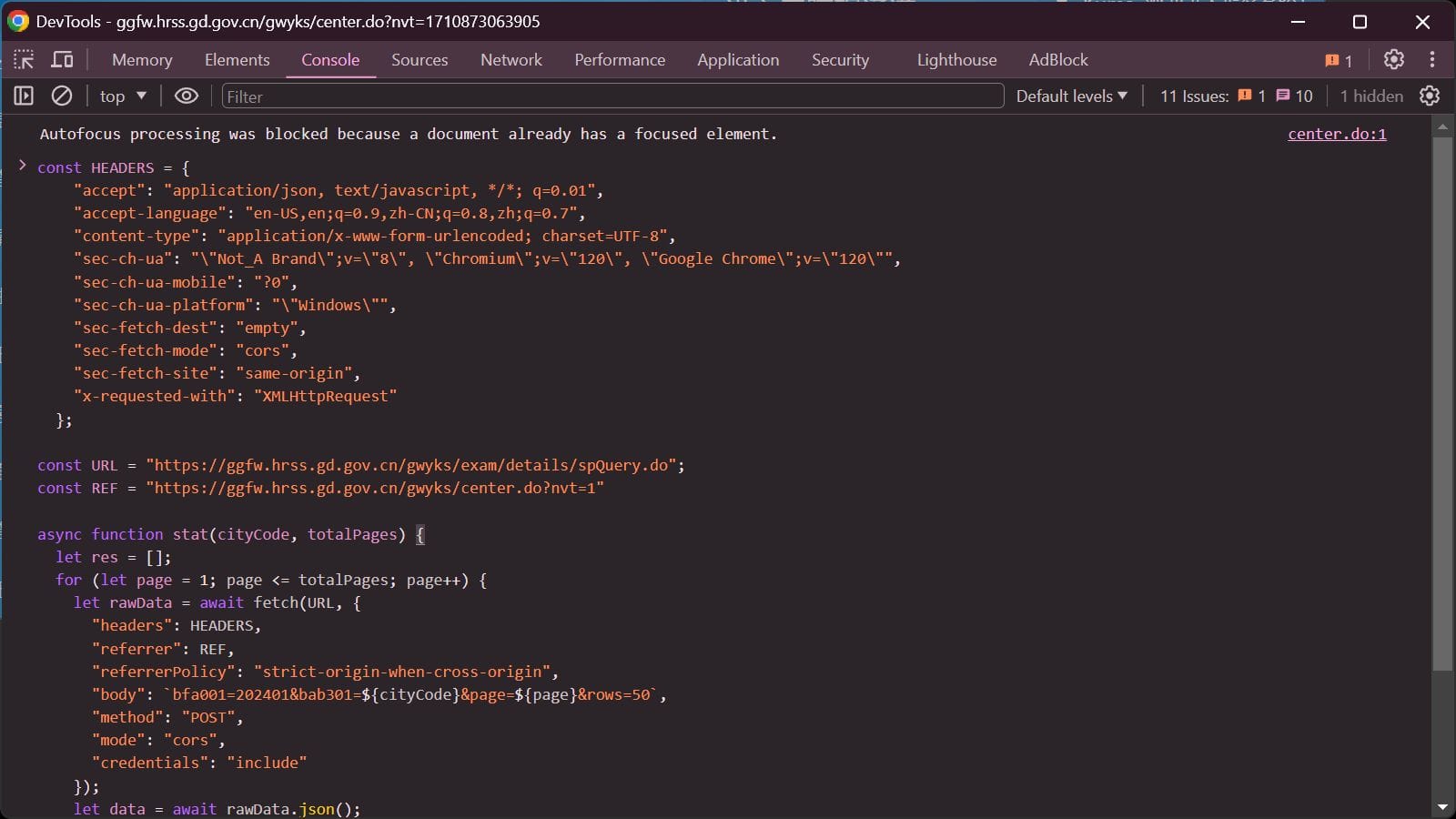
然后稍加修改,包装为 Function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| const HEADERS = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"sec-ch-ua": "\"Not_A Brand\";v=\"8\", \"Chromium\";v=\"120\", \"Google Chrome\";v=\"120\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-requested-with": "XMLHttpRequest"
};
const URL = "https://ggfw.hrss.gd.gov.cn/gwyks/exam/details/spQuery.do";
const REF = "https://ggfw.hrss.gd.gov.cn/gwyks/center.do?nvt=1"
async function stat(cityCode, totalPages) {
let res = [];
for (let page = 1; page <= totalPages; page++) {
let rawData = await fetch(URL, {
"headers": HEADERS,
"referrer": REF,
"referrerPolicy": "strict-origin-when-cross-origin",
"body": `bfa001=202401&bab301=${cityCode}&page=${page}&rows=50`,
"method": "POST",
"mode": "cors",
"credentials": "include"
});
let data = await rawData.json();
res = res.concat(data.rows);
console.log(`page ${page} done, ${data.rows.length} items added, total ${res.length} items`);
await new Promise(r => setTimeout(r, 2000));
}
return res;
}
|
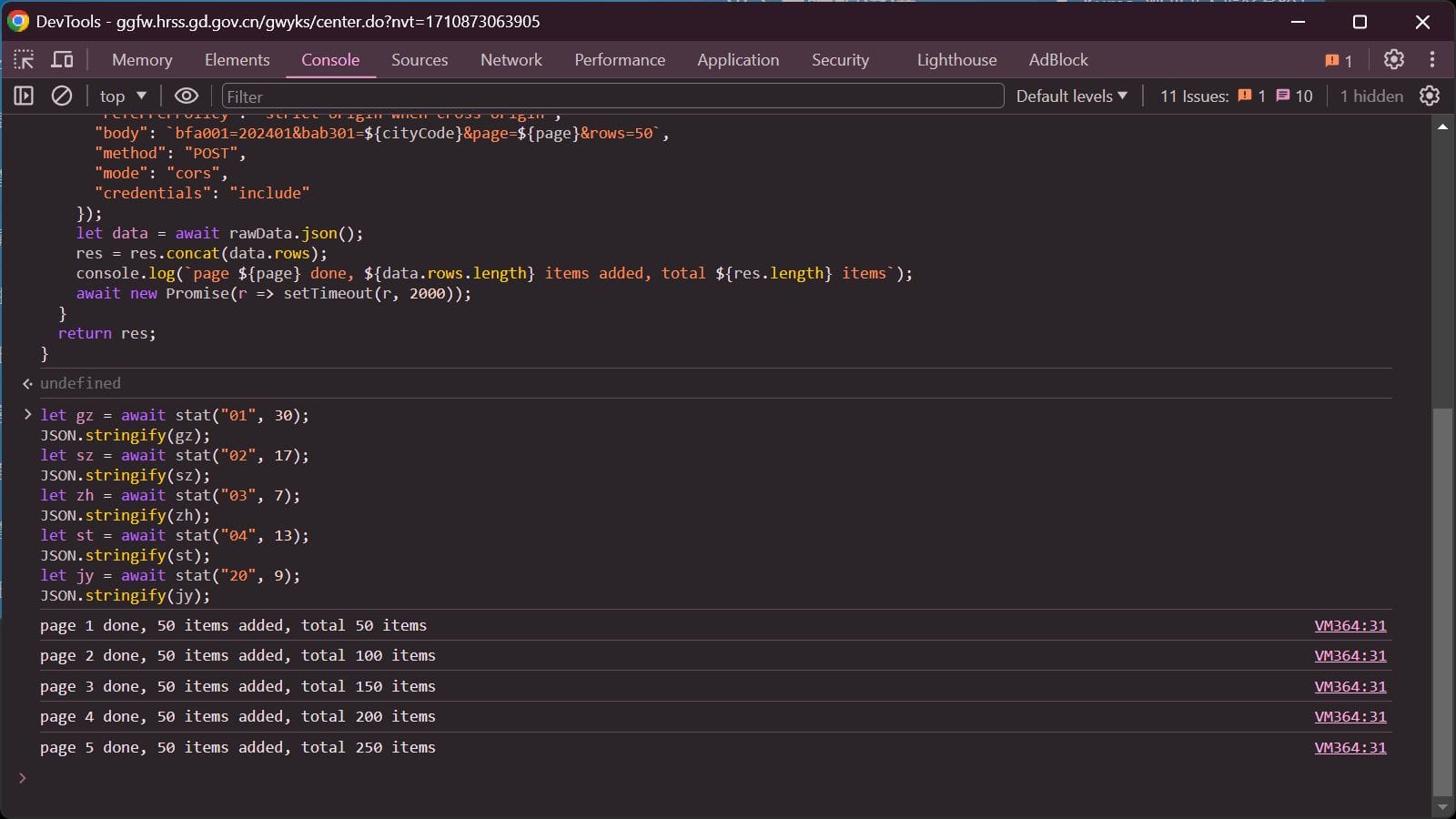
查询城市代码后调用:
1
2
| let gz = await stat("01", 30);
JSON.stringify(gz);
|
点击右下角 Copy 按钮即可复制:
处理 / Python
先将筛选出的职位代码保存到 query.txt,
随后即可编写代码,打印职位对应的报名人数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import json
JOB_KEY = 'bfe301'
POP_KEY = 'aab119'
def save_all():
gz = json.loads(eval(input('gz: ')))
sz = json.loads(eval(input('sz: ')))
data = gz + sz
with open('all.json', 'w') as f:
json.dump(data, f)
return data
def get_fmt_data(data):
fmt = {}
for item in data:
fmt[item[JOB_KEY]] = item
return fmt
def get_query():
with open('query.txt', 'r') as f:
query = f.readlines()
query = [i.strip() for i in query]
return query
if __name__ == '__main__':
all_data = save_all()
fmt_data = get_fmt_data(all_data)
to_query = get_query()
print(f'Total: {len(to_query)}')
for i in to_query:
if i in fmt_data:
print(fmt_data[i][POP_KEY])
else:
print('?')
|
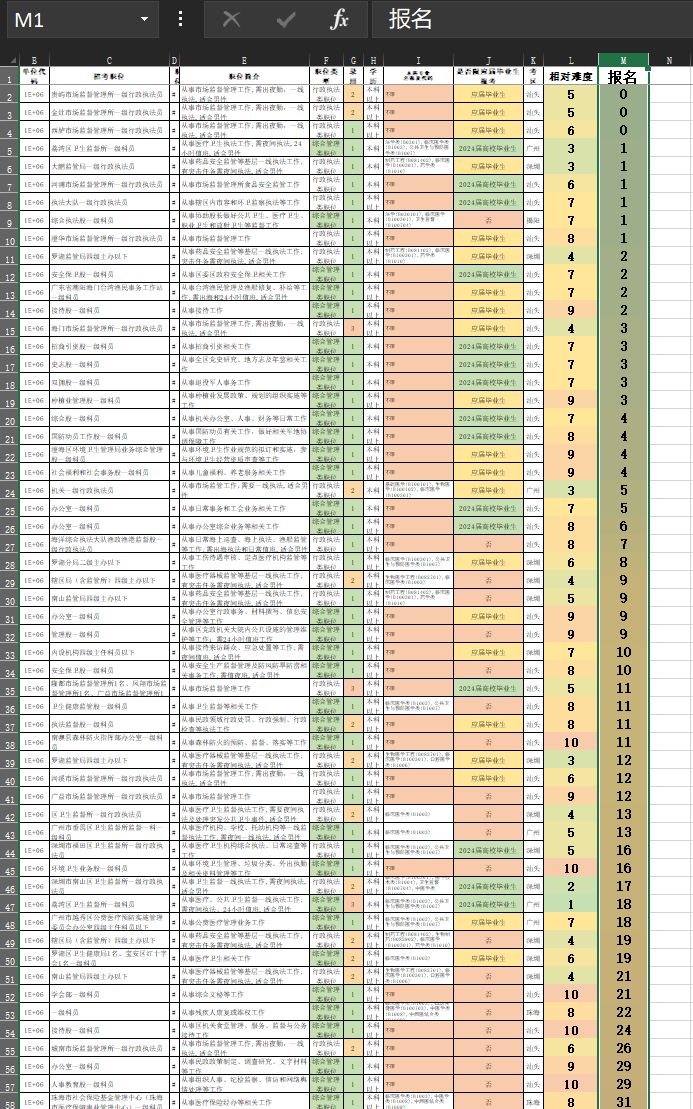
运行后,输入数据,控制台就会按照顺序打印出职位代码对应的人数。
粘贴到 Excel 中,就可以直观查看与比较两者:
其他技巧
本文所述技巧基于越迟报名,获取信息越多的前提,
但是需要审核个人信息通过后才能成功报名。
因此,一定要先点击左侧 个人信息 按钮,填好保存!!!
提交之后就会上报审核,与报名分开,
这样最后一天报名,提交后就直接通过,不用再等待审核。
结语
报名阶段自动化,最多只是筛选出相对容易上岸的职位,
美其名曰赢在起跑线上,但最终能否冲线还要看自己的体能。
另外,本文只是提供了一种减少重复操作的思路,
数据一天只会更新一次,请勿频繁查询,以免违反相关法律规定。
虽然机构应该有自己的编程大手子,
看不上我的这些蹩脚代码,但还是声明,严禁商用。
